java使用正则表达式
Pattern (java.util.regex.Pattern) java正则处理从这里开始
类 java.util.regex.Pattern 简称 Pattern, 是Java正则表达式API中的主要入口,无论何时,需要使用正则表达式,从Pattern 类开始
Pattern.matches()
静态调用matches()方法匹配,只能检查模式在文本中出现一次的情况 意思是(文本有没有符合模式的字符)
调用源码
1
2
3
4
5
|
String text ="This is the text to be searched " +
"for occurrences of the http:// pattern.";
String pattern = ".*http://.*";
boolean b = Pattern.matches(pattern, text); //这里静态调用matches()方法,直接使用Matcher类的matches()方法
assertEquals(true,b); //true
|
java 源码
1
2
3
4
5
|
public static boolean matches(String var0, CharSequence var1) {
Pattern var2 = compile(var0); //直接编译成Pattern
Matcher var3 = var2.matcher(var1); //得到Matcher对象
return var3.matches(); //调用Matcher 的matches() 方法
}
|
通过静态调用只能做简单的判断字符是否符合模式
java 通过将pattern 跟matcher分离 先的得到 pattern对象 跟据pattern对象提供的一些方法,正则不仅仅只做简单的判断完事,还可以分组替换查找位置等等
很多神奇的操作 而Matcher 就是帮助Pattern 实现这些方法
由此可见:
使用java正则有三步:
- 构建Pattern
- 得到Matcher
- 完成相应的操作
Pattern.compile(@notnull String,int) 构建Pattern 对象
参数: 1.要匹配的正则 2.pattern匹配方式 Pattern静态变量中可以选择需要的方式
调用源码
1
2
|
Pattern compile = Pattern.compile(pattern); //默认方式
Pattern.compile(pattern,Pattern.CASE_INSENSITIVE); //使用忽略大小写的方式
|
java源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public static Pattern compile(String var0) {
return new Pattern(var0, 0); //默认方式传如的是0
}
public static Pattern compile(String var0, int var1) {
return new Pattern(var0, var1); //通过构造器构造 自己
}
//我们看看方法到底在哪里实现
private Pattern(String var1, int var2) {
this.pattern = var1;
this.flags = var2;
if((this.flags & 256) != 0) {
this.flags |= 64;
}
this.capturingGroupCount = 1;
this.localCount = 0;
if(this.pattern.length() > 0) {
this.compile();
} else {
this.root = new Pattern.Start(lastAccept); //得到Pattern.node
this.matchRoot = lastAccept;
}
}
|
Pattern.matcher(@notnull String) 得到Matcher对象
参数:要匹配的字符串
调用代码
1
2
3
4
5
6
|
String text = "This is the text to be searched " +
"for occurrences of the http:// pattern.";
String pattern = ".*http://.*";
Pattern compile = Pattern.compile(pattern);
Matcher matcher = compile.matcher(text);
assertEquals(true, matcher.matches()); //调用matchers()方法实现匹配比较
|
java 源码
1
2
3
4
5
6
7
8
9
10
11
12
|
public Matcher matcher(CharSequence var1) {
if(!this.compiled) {
synchronized(this) {
if(!this.compiled) {
this.compile(); //判断是否编译过
}
}
}
Matcher var2 = new Matcher(this, var1); //实例化一个Matcher对象
return var2;
}
|
Pattern.split(@notnull String,int) 用正则表达式作为分隔符,把文本分割为String类型的数组。
参数: string:要分割的字符串 int分割处理的段数 也就是数组length 0全部分割 1原样输出不分割 2分割成两段 从第一个符合pattern处分割 之后以此类推
调用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
String text = "This is the text to be searched " +
"for occurrences of the http:// pattern.";
String pattern = ".*http://.*";
String pattern = " ";
Pattern compile = Pattern.compile(pattern);
String[] textArr = compile.split(text);
String res = "";
for (String s : textArr) {
res +=s;
}
assertEquals("Thisisthetexttobesearchedforoccurrencesofthehttp://pattern.",res);
String[] limitArr = compile.split(text, 2); //分割成两段 从第一符合正则处分割
for (String s : limitArr) {
System.out.println(s); //打印瞅瞅
}
assertEquals(2,limitArr.length);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
public String[] split(CharSequence input) {
return split(input, 0);//使用默认方式split
}
public String[] split(CharSequence input, int limit) { //limit限制数量
int index = 0;
boolean matchLimited = limit > 0;
ArrayList<String> matchList = new ArrayList<>();
Matcher m = matcher(input);
// Add segments before each match found
while(m.find()) {
if (!matchLimited || matchList.size() < limit - 1) {
if (index == 0 && index == m.start() && m.start() == m.end()) {
// no empty leading substring included for zero-width match
// at the beginning of the input char sequence.
continue;
}
String match = input.subSequence(index, m.start()).toString();
matchList.add(match);
index = m.end();
} else if (matchList.size() == limit - 1) { // last one
String match = input.subSequence(index,
input.length()).toString();
matchList.add(match);
index = m.end();
}
}
// If no match was found, return this 根据index的值来确定匹配数
if (index == 0)
return new String[] {input.toString()};
// Add remaining segment
if (!matchLimited || matchList.size() < limit)
matchList.add(input.subSequence(index, input.length()).toString());
// Construct result
int resultSize = matchList.size();
if (limit == 0)
while (resultSize > 0 && matchList.get(resultSize-1).equals(""))
resultSize--;
String[] result = new String[resultSize];
return matchList.subList(0, resultSize).toArray(result); //可以看到通过list 转的数组
}
|
Pattern.pattern() 返回创建pattern的pattern字符串对象
调用源码
1
2
3
4
|
String pattern = ".*http://.*";
Pattern compile = Pattern.compile(pattern);
String pattern1 = compile.pattern();
assertEquals(pattern,pattern1);
|
java 源码
1
2
3
|
public String pattern() { //果然返回的是Pattern.pattern
return pattern;
}
|
Matcher (java.util.regex.Matcher)
java.util.regex.Matcher 类用于匹配一段文本中多次出现一个正则表达式,Matcher 也适用于多文本中匹配同一个正则表达式。
通过Pattern创建Matcher对象
1
2
3
4
5
6
7
|
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = ".*http://.*";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(text);
|
matches() 调用matches() 方法进行匹配
matches() 方法不能用于查找正则表达式多次出现。如果需要,请使用find(), start() 和 end() 方法。
lookingAt()
lookingAt()方法对文本的开头匹配正则表达式;而matches() 对整个文本匹配正则表达式。换句话说,如果正则表达式匹配文本开头而不匹配整个文本,lookingAt() 返回true,而matches() 返回false。
调用代码
1
2
3
4
5
6
7
8
9
10
11
|
public void testMatcherLookAt(){
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = "This is the";
Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(text);
assertEquals(true, matcher.lookingAt()); //true 可以匹配开头 查找以pattern开头的字符串
assertEquals(false, matcher.matches());
//因为 整个文本包含多余的字符,而 正则表达式要求文本精确匹配
}
|
java 源码
1
2
3
|
public boolean lookingAt() {
return match(from, NOANCHOR);
}
|
理解Matcher的find() start() end() 方法
find() 方法用于在文本中查找出现的正则表达式,文本是创建Matcher时,通过 Pattern.matcher(text) 方法传入的。
如果在文本中多次匹配,find() 方法返回第一个,之后每次调用 find() 都会返回下一个。
start() 和 end() 返回每次匹配的字串在整个文本中的开始和结束位置。
实际上, end() 返回的是字符串末尾的后一位,这样,可以在把 start() 和 end() 的返回值直接用在String.substring() 里。
调用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
String patternString = "is";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(text);
int count = 0;
while (matcher.find()) {
count++;
System.out.println("found: " + count + " : " + matcher.start() + " - " + matcher.end());
}
/*
found: 1 : 2 - 4
found: 2 : 5 - 7
found: 3 : 23 - 25
found: 4 : 70 - 72
*/
|
reset()
reset() 方法会重置Matcher 内部的 匹配状态。当find() 方法开始匹配时,Matcher 内部会记录截至当前查找的距离。调用 reset() 会重新从文本开头查找。
也可以调用 reset(CharSequence) 方法. 这个方法重置Matcher,同时把一个新的字符串作为参数传入,用于代替创建 Matcher 的原始字符串。
group()
假设想在一个文本中查找URL链接,并且想把找到的链接提取出来。当然可以通过 start()和 end()方法完成。但是用group()方法更容易些。
分组在正则表达式中用括号表示: (John)
此正则表达式匹配John, 括号不属于要匹配的文本。括号定义了一个分组。当正则表达式匹配到文本后,可以访问分组内的部分。
使用group(int groupNo) 方法访问一个分组。一个正则表达式可以有多个分组。每个分组由一对括号标记。想要访问正则表达式中某分组匹配的文本,可以把分组编号传入 group(int groupNo)方法。
group(0) 表示整个正则表达式,要获得一个有括号标记的分组,分组编号应该从1开始计算。
调用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Test
public void testMatcherGroup(){
String text = "John writes about this, and John writes about that," +
" and John writes about everything. ";
String patternString1 = "(John)";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
while (matcher.find()) { //找到符合条件matcher
System.out.println("found: " + matcher.group(1)); //得到分组1中的值
}
}
/*
以上代码在文本中搜索单词John.从每个匹配文本中,提取分组1,就是由括号标记的部分。输出如下
found: John
found: John
found: John
*/
|
多分组
(John) (.+?)
这个表达式匹配文本”John” 后跟一个空格,然后跟1个或多个字符,最后跟一个空格。你可能看不到最后的空格。
这个表达式包括一些字符有特别意义。字符 点 . 表示任意字符。 字符 + 表示出现一个或多个,和. 在一起表示 任何字符,出现一次或多次。字符? 表示 匹配尽可能短的文本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Test
public void testMatcherMultiGroup(){
String text =
"John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything.";
String patternString1 = "(John) (.+?) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println("found: " + matcher.group(1) +
" " + matcher.group(2)); //获取分组2的内容
}
}
/*
found: John writes
found: John Doe
found: John Wayne
*/
|
嵌套分组
((John) (.+?))
这是之前的例子,现在放在一个大分组里.(表达式末尾有一个空格)。
当遇到嵌套分组时, 分组编号是由左括号的顺序确定的。上例中,分组1 是那个大分组。分组2 是包括John的分组,分组3 是包括 .+? 的分组。当需要通过groups(int groupNo) 引用分组时,了解这些非常重要。
代码调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
@Test
public void testNestGroup(){
String text = "John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything.";
String patternString1 = "((John) (.+?)) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println("found: "+matcher.group(1)); //此时将之前两个分组做为整体 输出 ,也可以group(2)和group(3)得到嵌套分组内的值
}
}
/*
found: John writes
found: John Doe
found: John Wayne
*/
|
replaceAll() + replaceFirst()
replaceAll() 和 replaceFirst() 方法可以用于替换Matcher搜索字符串中的一部分。replaceAll() 方法替换全部匹配的正则表达式,replaceFirst() 只替换第一个匹配的。
在处理之前,Matcher 会先重置。所以这里的匹配表达式从文本开头开始计算。
调用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Test
public void testMatcherReplace(){
String text = "John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything.";
String patternString1 = "((John) (.+?)) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
String replaceAll = matcher.replaceAll("Joe Blocks ");
System.out.println("replaceAll = " + replaceAll);
String replaceFirst = matcher.replaceFirst("Joe Blocks "); //显然只是替换开头的John writes 字符串
System.out.println("replaceFirst = " + replaceFirst);
}
/*
replaceAll = Joe Blocks about this, and Joe Blocks writes about that, and Joe Blocks writes about everything.
replaceFirst = Joe Blocks about this, and John Doe writes about that, and John Wayne writes about everything.
*/
|
appendReplacement() + appendTail()
appendReplacement() 和 appendTail() 方法用于替换输入文本中的字符串短语,同时把替换后的字符串附加到一个 StringBuffer 中。
当find() 方法找到一个匹配项时,可以调用 appendReplacement() 方法,这会导致输入字符串被增加到StringBuffer 中,而且匹配文本被替换。 从上一个匹配文本结尾处开始,直到本次匹配文本会被拷贝。
appendReplacement() 会记录拷贝StringBuffer 中的内容,可以持续调用find(),直到没有匹配项。
直到最后一个匹配项目,输入文本中剩余一部分没有拷贝到 StringBuffer. 这部分文本是从最后一个匹配项结尾,到文本末尾部分。通过调用 appendTail() 方法,可以把这部分内容拷贝到 StringBuffer 中.
调用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
@Test
public void testMatcherAppend(){
String text =
"John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything.";
String patternString1 = "((John) (.+?)) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
StringBuffer stringBuffer = new StringBuffer();
while (matcher.find()) {
matcher.appendReplacement(stringBuffer, "Joe Blocks ");
System.out.println(stringBuffer.toString()); //前三段将替换后的文本拷贝到stringbuffer中
}
matcher.appendTail(stringBuffer); //将最后一段没有匹配的matcher 放入stringbuffer中
System.out.println(stringBuffer.toString());
}
/*
Joe Blocks
Joe Blocks about this, and Joe Blocks
Joe Blocks about this, and Joe Blocks writes about that, and Joe Blocks
Joe Blocks about this, and Joe Blocks writes about that, and Joe Blocks writes about everything.
*/
|
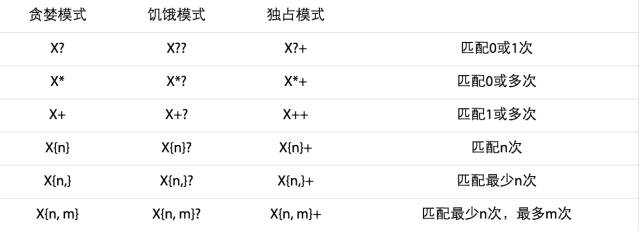
量词匹配
量词可以匹配一个表达式多次出现。例如下列表达式匹配字母A 出现0次或多次。
量词 * 表示0次或多次。+ 表示1次或多次。? 表示0次或1次。还有些其他量词,参见本文后面的列表。
量词匹配分为 饥饿模式,贪婪模式,独占模式。饥饿模式 匹配尽可能少的文本。贪婪模式匹配尽可能多的文本。独占模式匹配尽可能多的文本,甚至导致剩余表达式匹配失败。
文本: John went for a walk, and John fell down, and John hurt his knee.
饥饿模式: John.?
贪婪模式: John.
独占模式: John.*+hurt
独占模式会尽可能的多的匹配,但不考虑表达式剩余部分是否能匹配上。
量词